Introduction
As part of our AMM design for caviar we need to classify NFTs into separate bins based on their desirability relative to the rest of their respective collections. For example, if we have four subpools in the AMM for floor, mid, rare, and super-rare NFTs we need to be able to separate and classify each NFT into its appropriate pool.
Generating reliable and accurate NFT appraisals is already a problem that is being worked on by multiple teams. We can leverage existing work and get a robust classifier by taking multiple estimates from these existing sources and aggregating them together. In particular we will use spicyest, upshot, nabu and nftbank. Each of these providers uses unique models and methodologies. By aggregating them together, we can increase the reliability of our classifier.
Method
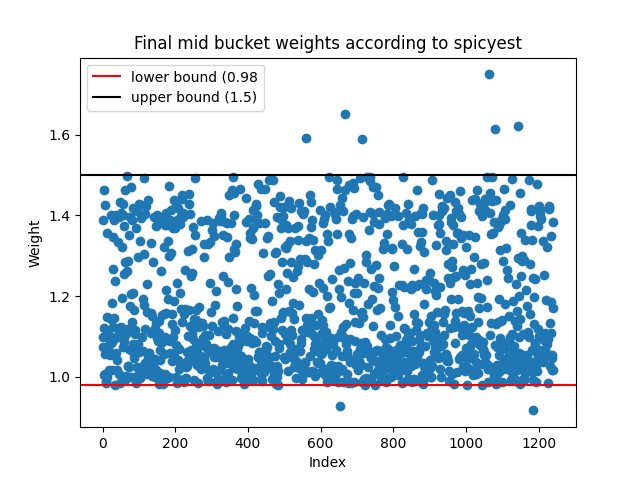
Let's walk through an example to see how we generate the desirability buckets from scratch. In this example, we will use Azukis. The first step is to fetch price estimates for the entire collection from spicyest, upshot, and nabu and then normalize each estimate against the floor price. If the floor price is 1.5 ETH and the NFT's price is 1.65 ETH then the weight (or normalized value) of that NFT is 1.65 / 1.5 = 1.1. Here are the results for spicyest:
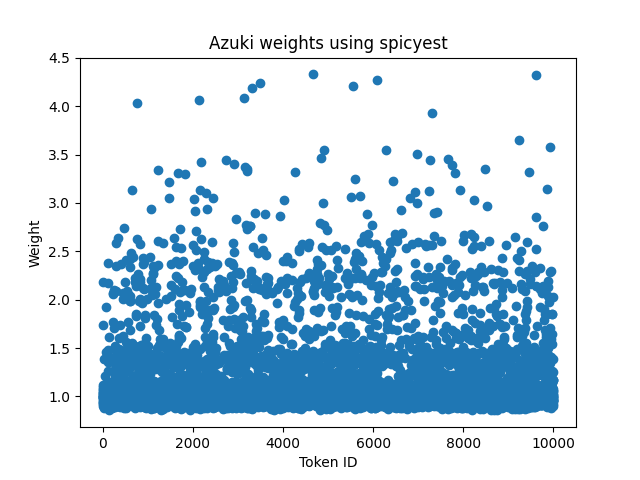
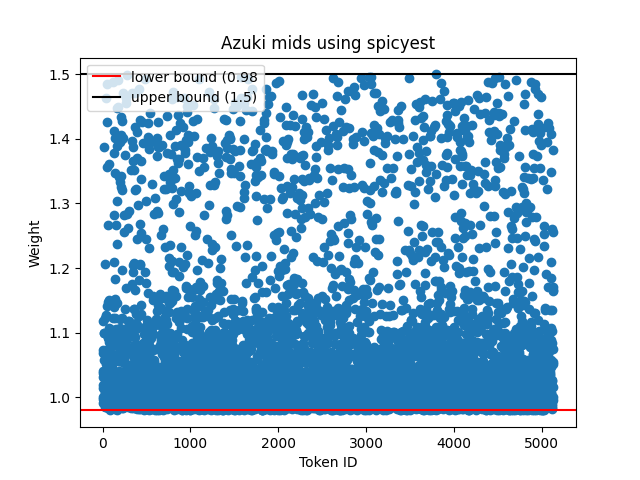
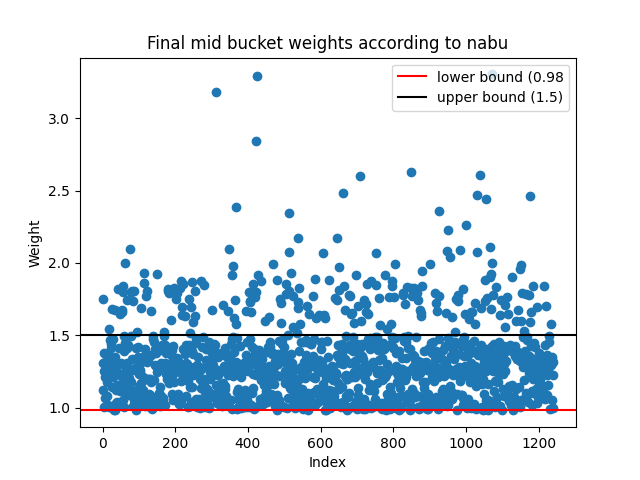
We can then generate an appropriate threshold for classifying into buckets. Ideally, we want as many NFTs as possible in each bucket and for each NFT within their buckets to be of a similar value. The threshold for what constitutes "similar" is subjective; if volatility is high and liquidity is low, then the upper and lower bounds of the bucket can be larger. For the mid-desirability bucket of Azukis, we chose a lower bound of 0.98 and an upper bound of 1.5. This gives us 2460 NFTs in the mid-bucket.
Now we can incorporate the results from upshot, nabu and nftbank. If we compare the bucket generated from spicyest predictions against upshot's and nabu's predictions we can see that there is a bit of variance:
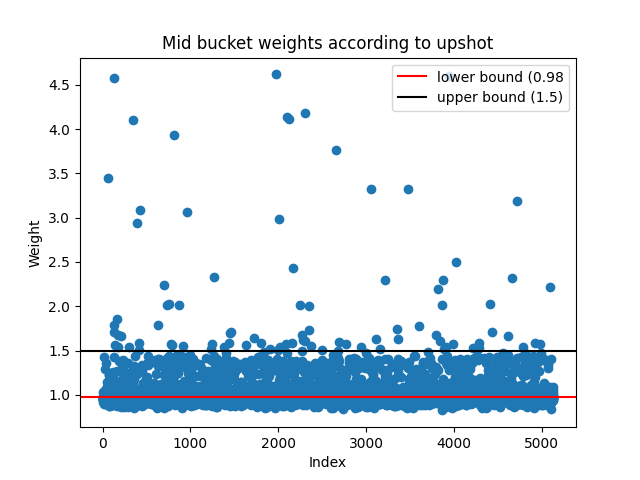
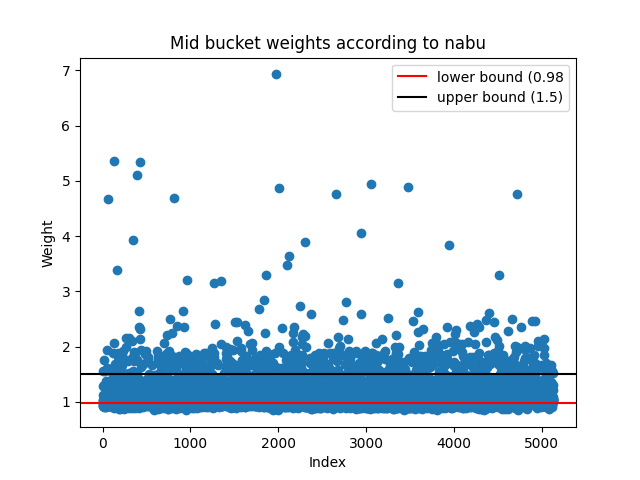
We can simply filter out all of the NFTs where there is disagreement. In particular, we only classify an NFT into a bucket if at least three out of the four weight estimates from the providers match up. Following this new "majority consensus" method yields much better results for all of the upshot, spicyest and nabu mid-bucket predictions:

Future work
It is probably obvious that by improving the models and incorporating more data, we can get more accurate classifications. In the future, we will include more models as they are released from other providers. We are also researching our own appraisal methods with a strong focus on classifying NFTs into desirability bins.
If you would like to find out more, feel free to reach out or follow us on twitter. The code for generating these results can be found on github here.